Linux 内核 Switchdev 代码阅读笔记
上一篇文章Linux 内核 Switchdev 框架学习笔记学习了switchdev框架的整体结构,主要参考是内核文档目录Documentation/networking/中的文件switchdev.rst(Linux 6.5),细节部分不同内核版本可能会有些出入,翻译部分居多,同时增加了自己的一些理解和思考,请酌情参考。
switchdev这个框架充分利用了Linux内核协议栈的特性,通过swtichdev提供的api来连接网络子系统和芯片驱动,以便厂商根据自己的支持情况卸载相应的特性到芯片上。程序员界有句话叫做“Talk is cheap, show me your code”,那么接下来我们就看看内核中的switchdev具体是如何实现的。
在内核的Documentation下搜索switchdev相关文件,得到如下结果:
./networking/device_drivers/ethernet/mellanox/mlx5/switchdev.rst
./networking/device_drivers/ethernet/ti/am65_nuss_cpsw_switchdev.rst
./networking/device_drivers/ethernet/ti/cpsw_switchdev.rst
./networking/switchdev.rst
./output/.doctrees/networking/device_drivers/ethernet/mellanox/mlx5/switchdev.doctree
./output/.doctrees/networking/device_drivers/ethernet/ti/am65_nuss_cpsw_switchdev.doctree
./output/.doctrees/networking/device_drivers/ethernet/ti/cpsw_switchdev.doctree
./output/.doctrees/networking/switchdev.doctree
./output/networking/device_drivers/ethernet/mellanox/mlx5/switchdev.html
./output/networking/device_drivers/ethernet/ti/am65_nuss_cpsw_switchdev.html
./output/networking/device_drivers/ethernet/ti/cpsw_switchdev.html
./output/networking/switchdev.html
./output/_sources/networking/device_drivers/ethernet/mellanox/mlx5/switchdev.rst.txt
./output/_sources/networking/device_drivers/ethernet/ti/am65_nuss_cpsw_switchdev.rst.txt
./output/_sources/networking/device_drivers/ethernet/ti/cpsw_switchdev.rst.txt
./output/_sources/networking/switchdev.rst.txt
在除了Documentation之外其他代码目录搜索switchdev,得到如下结果:
./drivers/net/dsa/mv88e6xxx/switchdev.c
./drivers/net/dsa/mv88e6xxx/switchdev.h
./drivers/net/ethernet/marvell/prestera/prestera_switchdev.c
./drivers/net/ethernet/marvell/prestera/prestera_switchdev.h
./drivers/net/ethernet/mellanox/mlxsw/spectrum_switchdev.c
./drivers/net/ethernet/mellanox/mlxsw/spectrum_switchdev.h
./drivers/net/ethernet/microchip/lan966x/lan966x_switchdev.c
./drivers/net/ethernet/microchip/sparx5/sparx5_switchdev.c
./drivers/net/ethernet/ti/am65-cpsw-switchdev.c
./drivers/net/ethernet/ti/am65-cpsw-switchdev.h
./drivers/net/ethernet/ti/cpsw_switchdev.c
./drivers/net/ethernet/ti/cpsw_switchdev.h
./drivers/net/wireless/quantenna/qtnfmac/switchdev.h
./include/net/switchdev.h
./net/bridge/br_mrp_switchdev.c
./net/bridge/br_switchdev.c
./net/switchdev
./net/switchdev/switchdev.c从上面文档和代码的搜索结果看,switchdev框架主要实现在net/switchdev目录下,bridge和dsa功能涉及switchdev接口,而支持的厂商及芯片主要有TI(cpsw),Microchip(sparx5, lan966x),Marvell(prestera), Mellanox(spectrum),以及专门为了展示switchdev而开发的rocker驱动。接下来我们就从这些方面看看switchdev是如何融入到Linux的网络子系统中的,主要以rocker驱动为主,并简单介绍芯片厂商的实现。
接口动态注册
在rocker_probe(rocker_main.c)函数中,通过rocker_probe_ports来遍历所有端口的初始化工作。代码片段如下:
static int rocker_probe(struct pci_dev *pdev, const struct pci_device_id *id)
{
...
err = rocker_probe_ports(rocker);
if (err) {
dev_err(&pdev->dev, "failed to probe ports\n");
goto err_probe_ports;
}
...
}其中rocker_probe_ports的实现如下:
static int rocker_probe_ports(struct rocker *rocker)
{
int i;
size_t alloc_size;
int err;
alloc_size = sizeof(struct rocker_port *) * rocker->port_count;
rocker->ports = kzalloc(alloc_size, GFP_KERNEL);
if (!rocker->ports)
return -ENOMEM;
for (i = 0; i < rocker->port_count; i++) {
err = rocker_probe_port(rocker, i);
if (err)
goto remove_ports;
}
return 0;
remove_ports:
rocker_remove_ports(rocker);
return err;
}其中rocker_probe_port完成实际端口的注册工作,具体如下:
static int rocker_probe_port(struct rocker *rocker, unsigned int port_number)
{
struct pci_dev *pdev = rocker->pdev;
struct rocker_port *rocker_port;
struct net_device *dev;
int err;
dev = alloc_etherdev(sizeof(struct rocker_port));
if (!dev)
return -ENOMEM;
SET_NETDEV_DEV(dev, &pdev->dev);
rocker_port = netdev_priv(dev);
rocker_port->dev = dev;
rocker_port->rocker = rocker;
rocker_port->port_number = port_number;
rocker_port->pport = port_number + 1;
err = rocker_world_check_init(rocker_port);
if (err) {
dev_err(&pdev->dev, "world init failed\n");
goto err_world_check_init;
}
rocker_port_dev_addr_init(rocker_port);
dev->netdev_ops = &rocker_port_netdev_ops;
dev->ethtool_ops = &rocker_port_ethtool_ops;
netif_napi_add_tx(dev, &rocker_port->napi_tx, rocker_port_poll_tx);
netif_napi_add(dev, &rocker_port->napi_rx, rocker_port_poll_rx);
rocker_carrier_init(rocker_port);
dev->features |= NETIF_F_NETNS_LOCAL | NETIF_F_SG;
/* MTU range: 68 - 9000 */
dev->min_mtu = ROCKER_PORT_MIN_MTU;
dev->max_mtu = ROCKER_PORT_MAX_MTU;
err = rocker_world_port_pre_init(rocker_port);
if (err) {
dev_err(&pdev->dev, "port world pre-init failed\n");
goto err_world_port_pre_init;
}
err = register_netdev(dev);
if (err) {
dev_err(&pdev->dev, "register_netdev failed\n");
goto err_register_netdev;
}
rocker->ports[port_number] = rocker_port;
err = rocker_world_port_init(rocker_port);
if (err) {
dev_err(&pdev->dev, "port world init failed\n");
goto err_world_port_init;
}
return 0;
err_world_port_init:
rocker->ports[port_number] = NULL;
unregister_netdev(dev);
err_register_netdev:
rocker_world_port_post_fini(rocker_port);
err_world_port_pre_init:
err_world_check_init:
free_netdev(dev);
return err;
}如果你对网卡驱动很熟悉的话,那么对上述代码也不会陌生。是的,rocker驱动会为每个port通过register_netdev注册一个net_device到网络子系统中,这样通过ifconfig/ip命令就可以看到这个接口了。这样芯片支持多少个口就注册了多少了net_device结构,也可以将交换芯片理解为一个很多网口(一般的网卡支持1/2/4个网口)的网卡,后面都将交换芯片看做网卡,很多东西就可以容易理解了,比如支持ethtool工具,而这也是switchdev驱动设计的初衷——用通用Linux操作系统来管理交换机设备。rocker_port是rocker驱动自己管理端口的私有数据结构,或者说是网卡管理网口的私有数据结构。
当然,绝大部分网卡都支持动态插拔,类比网卡的交换驱动也支持卸载,rocker驱动对应的就是rocker_remove,具体实现就是动态删除所有的管理资源,这里就不详细描述了。
中断和DMA
除了接口资源,rocker_probe中还注册了中断处理程序和dma环形缓冲区,这些也是网卡驱动必须实现的功能,部分代码如下:
static int rocker_probe(struct pci_dev *pdev, const struct pci_device_id *id)
{
...
err = rocker_dma_rings_init(rocker);
if (err)
goto err_dma_rings_init;
err = request_irq(rocker_msix_vector(rocker, ROCKER_MSIX_VEC_CMD),
rocker_cmd_irq_handler, 0,
rocker_driver_name, rocker);
if (err) {
dev_err(&pdev->dev, "cannot assign cmd irq\n");
goto err_request_cmd_irq;
}
err = request_irq(rocker_msix_vector(rocker, ROCKER_MSIX_VEC_EVENT),
rocker_event_irq_handler, 0,
rocker_driver_name, rocker);
if (err) {
dev_err(&pdev->dev, "cannot assign event irq\n");
goto err_request_event_irq;
}
...
}这里有一个dma ring初始化rocker_dma_rings_init,以及两个中断处理函数rocker_cmd_irq_handler和rocker_event_irq_handler,看起来和一般的网卡驱动是不是有些不同了。除了这两个中断外,在上述netdev_ops的回调函数rocker_port_netdev_ops中注册的rocker_port_open中,还分别初始化了一个dma ring,以及注册了两个中断处理函数,具体代码如下:
static int rocker_port_open(struct net_device *dev)
{
struct rocker_port *rocker_port = netdev_priv(dev);
int err;
err = rocker_port_dma_rings_init(rocker_port);
if (err)
return err;
err = request_irq(rocker_msix_tx_vector(rocker_port),
rocker_tx_irq_handler, 0,
rocker_driver_name, rocker_port);
if (err) {
netdev_err(rocker_port->dev, "cannot assign tx irq\n");
goto err_request_tx_irq;
}
err = request_irq(rocker_msix_rx_vector(rocker_port),
rocker_rx_irq_handler, 0,
rocker_driver_name, rocker_port);
if (err) {
netdev_err(rocker_port->dev, "cannot assign rx irq\n");
goto err_request_rx_irq;
}
err = rocker_world_port_open(rocker_port);
if (err) {
netdev_err(rocker_port->dev, "cannot open port in world\n");
goto err_world_port_open;
}
napi_enable(&rocker_port->napi_tx);
napi_enable(&rocker_port->napi_rx);
if (!dev->proto_down)
rocker_port_set_enable(rocker_port, true);
netif_start_queue(dev);
return 0;
err_world_port_open:
free_irq(rocker_msix_rx_vector(rocker_port), rocker_port);
err_request_rx_irq:
free_irq(rocker_msix_tx_vector(rocker_port), rocker_port);
err_request_tx_irq:
rocker_port_dma_rings_fini(rocker_port);
return err;
}等等,这是怎么回事,为什么有这么多的dma ring和irq?一般的网卡没有这么复杂啊!
让我们来仔细分析一下具体代码。
rocker_dma_rings_init中实际初始化了两个dma ring,分别是cmd_ring和event_ring,他们对应下面两个中断处理函数的DMA buffer。
rocker_cmd_irq_handler中断处理函数中,通过处理cmd_ring中的desc_info,来唤醒wait等待队列。
static irqreturn_t rocker_cmd_irq_handler(int irq, void *dev_id)
{
struct rocker *rocker = dev_id;
const struct rocker_desc_info *desc_info;
struct rocker_wait *wait;
u32 credits = 0;
spin_lock(&rocker->cmd_ring_lock);
while ((desc_info = rocker_desc_tail_get(&rocker->cmd_ring))) {
wait = rocker_desc_cookie_ptr_get(desc_info);
if (wait->nowait) {
rocker_desc_gen_clear(desc_info);
} else {
rocker_wait_wake_up(wait);
}
credits++;
}
spin_unlock(&rocker->cmd_ring_lock);
rocker_dma_ring_credits_set(rocker, &rocker->cmd_ring, credits);
return IRQ_HANDLED;
}
队列实际的处理在rocker_cmd_exec中,该函数获取cmd_ring中的desc_info,然后设置wait队列状态,调用传入的prepare做预处理后,最终触发cmd中断(通过rocker_desc_head_set设置desc为head),然后通过rocker_wait_event_timeout处理中断消息,最后调用传入process回调函数完成具体的功能。
int rocker_cmd_exec(struct rocker_port *rocker_port, bool nowait,
rocker_cmd_prep_cb_t prepare, void *prepare_priv,
rocker_cmd_proc_cb_t process, void *process_priv)
{
struct rocker *rocker = rocker_port->rocker;
struct rocker_desc_info *desc_info;
struct rocker_wait *wait;
unsigned long lock_flags;
int err;
spin_lock_irqsave(&rocker->cmd_ring_lock, lock_flags);
desc_info = rocker_desc_head_get(&rocker->cmd_ring);
if (!desc_info) {
spin_unlock_irqrestore(&rocker->cmd_ring_lock, lock_flags);
return -EAGAIN;
}
wait = rocker_desc_cookie_ptr_get(desc_info);
rocker_wait_init(wait);
wait->nowait = nowait;
err = prepare(rocker_port, desc_info, prepare_priv);
if (err) {
spin_unlock_irqrestore(&rocker->cmd_ring_lock, lock_flags);
return err;
}
rocker_desc_head_set(rocker, &rocker->cmd_ring, desc_info);
spin_unlock_irqrestore(&rocker->cmd_ring_lock, lock_flags);
if (nowait)
return 0;
if (!rocker_wait_event_timeout(wait, HZ / 10))
return -EIO;
err = rocker_desc_err(desc_info);
if (err)
return err;
if (process)
err = process(rocker_port, desc_info, process_priv);
rocker_desc_gen_clear(desc_info);
return err;
}上面就是一条命令的执行逻辑,简要说就是通过prepare回调构造desc_info,里面包含get/set命令字,以及port索引等,然后通过rocker_desc_head_set触发Rocker设备执行上述命令,Rocker设备完成后将返回结果放到desc_info中后触发中断,rocker_wait_event_timeout捕获中断后,通过rocker_desc_err判断是否有错误产生,如果没有错误,则调用process处理返回的desc_info,将结果拷贝到用户数据中。
在rocker代码中对应ethtool_ops注册的回调函数。
static int
rocker_cmd_get_port_settings_ethtool(struct rocker_port *rocker_port,
struct ethtool_link_ksettings *ecmd)
{
return rocker_cmd_exec(rocker_port, false,
rocker_cmd_get_port_settings_prep, NULL,
rocker_cmd_get_port_settings_ethtool_proc,
ecmd);
}
static int rocker_cmd_get_port_settings_macaddr(struct rocker_port *rocker_port,
unsigned char *macaddr)
{
return rocker_cmd_exec(rocker_port, false,
rocker_cmd_get_port_settings_prep, NULL,
rocker_cmd_get_port_settings_macaddr_proc,
macaddr);
}
static int rocker_cmd_get_port_settings_mode(struct rocker_port *rocker_port,
u8 *p_mode)
{
return rocker_cmd_exec(rocker_port, false,
rocker_cmd_get_port_settings_prep, NULL,
rocker_cmd_get_port_settings_mode_proc, p_mode);
}
static int
rocker_cmd_set_port_settings_ethtool(struct rocker_port *rocker_port,
const struct ethtool_link_ksettings *ecmd)
{
struct ethtool_link_ksettings copy_ecmd;
memcpy(©_ecmd, ecmd, sizeof(copy_ecmd));
return rocker_cmd_exec(rocker_port, false,
rocker_cmd_set_port_settings_ethtool_prep,
©_ecmd, NULL, NULL);
}注意,上面set接口实际是没有注册process回调的,因为prepare中已经把配置信息下发了,中断完成后直接返回即可。
以及通过netdev_ops注册的回调函数,set接口也是没有process处理的:
static int rocker_cmd_set_port_settings_macaddr(struct rocker_port *rocker_port,
unsigned char *macaddr)
{
return rocker_cmd_exec(rocker_port, false,
rocker_cmd_set_port_settings_macaddr_prep,
macaddr, NULL, NULL);
}
static int rocker_cmd_set_port_settings_mtu(struct rocker_port *rocker_port,
int mtu)
{
return rocker_cmd_exec(rocker_port, false,
rocker_cmd_set_port_settings_mtu_prep,
&mtu, NULL, NULL);
}
int rocker_port_set_learning(struct rocker_port *rocker_port,
bool learning)
{
return rocker_cmd_exec(rocker_port, false,
rocker_cmd_set_port_learning_prep,
&learning, NULL, NULL);
}rocker_event_irq_handler中断处理函数中,通过处理event_ring中的desc_info,调用rocker_event_process做进一步的处理。
static irqreturn_t rocker_event_irq_handler(int irq, void *dev_id)
{
struct rocker *rocker = dev_id;
const struct pci_dev *pdev = rocker->pdev;
const struct rocker_desc_info *desc_info;
u32 credits = 0;
int err;
while ((desc_info = rocker_desc_tail_get(&rocker->event_ring))) {
err = rocker_desc_err(desc_info);
if (err) {
dev_err(&pdev->dev, "event desc received with err %d\n",
err);
} else {
err = rocker_event_process(rocker, desc_info);
if (err)
dev_err(&pdev->dev, "event processing failed with err %d\n",
err);
}
rocker_desc_gen_clear(desc_info);
rocker_desc_head_set(rocker, &rocker->event_ring, desc_info);
credits++;
}
rocker_dma_ring_credits_set(rocker, &rocker->event_ring, credits);
return IRQ_HANDLED;
}rocker_event_process中对解析desc_info,根据type类型处理link变化事件和mac/vlan事件。
static int rocker_event_process(const struct rocker *rocker,
const struct rocker_desc_info *desc_info)
{
const struct rocker_tlv *attrs[ROCKER_TLV_EVENT_MAX + 1];
const struct rocker_tlv *info;
u16 type;
rocker_tlv_parse_desc(attrs, ROCKER_TLV_EVENT_MAX, desc_info);
if (!attrs[ROCKER_TLV_EVENT_TYPE] ||
!attrs[ROCKER_TLV_EVENT_INFO])
return -EIO;
type = rocker_tlv_get_u16(attrs[ROCKER_TLV_EVENT_TYPE]);
info = attrs[ROCKER_TLV_EVENT_INFO];
switch (type) {
case ROCKER_TLV_EVENT_TYPE_LINK_CHANGED:
return rocker_event_link_change(rocker, info);
case ROCKER_TLV_EVENT_TYPE_MAC_VLAN_SEEN:
return rocker_event_mac_vlan_seen(rocker, info);
}
return -EOPNOTSUPP;
}从上面我们可以看到,所有的配置和状态获取都是通过cmd_ring,而所有的事件触发都来自event_ring,也就是说rocker通过cmd_ring和event_ring模拟了交换芯片的具体功能,那么是谁向cmd_ring和event_ring中放入数据的呢?继续看,我们后面会揭开这个谜底。
rocker_port_dma_rings_init中实际初始化了两个dma ring,分别是tx_ring和rx_ring,他们对应下面两个中断处理函数的DMA buffer。。
rocker_tx_irq_handler中断处理函数中,通过napi_schedule触发napi_tx注册的回调rocker_port_poll_tx。
static irqreturn_t rocker_tx_irq_handler(int irq, void *dev_id)
{
struct rocker_port *rocker_port = dev_id;
napi_schedule(&rocker_port->napi_tx);
return IRQ_HANDLED;
}函数rocker_port_poll_tx中处理tx_ring缓冲区的内容,此时报文已经发送完成,释放skb报文,完成budget额度后通过napi_complete通知napi停止轮询调度。
static int rocker_port_poll_tx(struct napi_struct *napi, int budget)
{
struct rocker_port *rocker_port = rocker_port_napi_tx_get(napi);
const struct rocker *rocker = rocker_port->rocker;
const struct rocker_desc_info *desc_info;
u32 credits = 0;
int err;
/* Cleanup tx descriptors */
while ((desc_info = rocker_desc_tail_get(&rocker_port->tx_ring))) {
struct sk_buff *skb;
err = rocker_desc_err(desc_info);
if (err && net_ratelimit())
netdev_err(rocker_port->dev, "tx desc received with err %d\n",
err);
rocker_tx_desc_frags_unmap(rocker_port, desc_info);
skb = rocker_desc_cookie_ptr_get(desc_info);
if (err == 0) {
rocker_port->dev->stats.tx_packets++;
rocker_port->dev->stats.tx_bytes += skb->len;
} else {
rocker_port->dev->stats.tx_errors++;
}
dev_kfree_skb_any(skb);
credits++;
}
if (credits && netif_queue_stopped(rocker_port->dev))
netif_wake_queue(rocker_port->dev);
napi_complete(napi);
rocker_dma_ring_credits_set(rocker, &rocker_port->tx_ring, credits);
return 0;
}上面是发送中断处理,实际的驱动发包在回调函数ndo_start_xmit对应的接口rocker_port_xmit中。此函数找到skb对应的desc_info,填充内容后放到tx_ring中,完成报文发送。
static netdev_tx_t rocker_port_xmit(struct sk_buff *skb, struct net_device *dev)
{
struct rocker_port *rocker_port = netdev_priv(dev);
struct rocker *rocker = rocker_port->rocker;
struct rocker_desc_info *desc_info;
struct rocker_tlv *frags;
int i;
int err;
desc_info = rocker_desc_head_get(&rocker_port->tx_ring);
if (unlikely(!desc_info)) {
if (net_ratelimit())
netdev_err(dev, "tx ring full when queue awake\n");
return NETDEV_TX_BUSY;
}
rocker_desc_cookie_ptr_set(desc_info, skb);
frags = rocker_tlv_nest_start(desc_info, ROCKER_TLV_TX_FRAGS);
if (!frags)
goto out;
err = rocker_tx_desc_frag_map_put(rocker_port, desc_info,
skb->data, skb_headlen(skb));
if (err)
goto nest_cancel;
if (skb_shinfo(skb)->nr_frags > ROCKER_TX_FRAGS_MAX) {
err = skb_linearize(skb);
if (err)
goto unmap_frags;
}
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
const skb_frag_t *frag = &skb_shinfo(skb)->frags[i];
err = rocker_tx_desc_frag_map_put(rocker_port, desc_info,
skb_frag_address(frag),
skb_frag_size(frag));
if (err)
goto unmap_frags;
}
rocker_tlv_nest_end(desc_info, frags);
rocker_desc_gen_clear(desc_info);
rocker_desc_head_set(rocker, &rocker_port->tx_ring, desc_info);
desc_info = rocker_desc_head_get(&rocker_port->tx_ring);
if (!desc_info)
netif_stop_queue(dev);
return NETDEV_TX_OK;
unmap_frags:
rocker_tx_desc_frags_unmap(rocker_port, desc_info);
nest_cancel:
rocker_tlv_nest_cancel(desc_info, frags);
out:
dev_kfree_skb(skb);
dev->stats.tx_dropped++;
return NETDEV_TX_OK;
}rocker_rx_irq_handler中断处理函数中,通过napi_schedule触发napi_rx注册的回调rocker_port_poll_rx。
static irqreturn_t rocker_rx_irq_handler(int irq, void *dev_id)
{
struct rocker_port *rocker_port = dev_id;
napi_schedule(&rocker_port->napi_rx);
return IRQ_HANDLED;
}函数rocker_port_poll_rx中处理rx_ring缓冲区的内容,获取desc_info,调用rocker_port_rx_proc处理,完成budget额度后通过napi_complete_done通知napi停止轮询调度。
static int rocker_port_poll_rx(struct napi_struct *napi, int budget)
{
struct rocker_port *rocker_port = rocker_port_napi_rx_get(napi);
const struct rocker *rocker = rocker_port->rocker;
struct rocker_desc_info *desc_info;
u32 credits = 0;
int err;
/* Process rx descriptors */
while (credits < budget &&
(desc_info = rocker_desc_tail_get(&rocker_port->rx_ring))) {
err = rocker_desc_err(desc_info);
if (err) {
if (net_ratelimit())
netdev_err(rocker_port->dev, "rx desc received with err %d\n",
err);
} else {
err = rocker_port_rx_proc(rocker, rocker_port,
desc_info);
if (err && net_ratelimit())
netdev_err(rocker_port->dev, "rx processing failed with err %d\n",
err);
}
if (err)
rocker_port->dev->stats.rx_errors++;
rocker_desc_gen_clear(desc_info);
rocker_desc_head_set(rocker, &rocker_port->rx_ring, desc_info);
credits++;
}
if (credits < budget)
napi_complete_done(napi, credits);
rocker_dma_ring_credits_set(rocker, &rocker_port->rx_ring, credits);
return credits;
}rocker_port_rx_proc函数中获取desc_info对应的skb,填充内容后通过netif_receive_skb上交内核网络协议栈处理。
static int rocker_port_rx_proc(const struct rocker *rocker,
const struct rocker_port *rocker_port,
struct rocker_desc_info *desc_info)
{
const struct rocker_tlv *attrs[ROCKER_TLV_RX_MAX + 1];
struct sk_buff *skb = rocker_desc_cookie_ptr_get(desc_info);
size_t rx_len;
u16 rx_flags = 0;
if (!skb)
return -ENOENT;
rocker_tlv_parse_desc(attrs, ROCKER_TLV_RX_MAX, desc_info);
if (!attrs[ROCKER_TLV_RX_FRAG_LEN])
return -EINVAL;
if (attrs[ROCKER_TLV_RX_FLAGS])
rx_flags = rocker_tlv_get_u16(attrs[ROCKER_TLV_RX_FLAGS]);
rocker_dma_rx_ring_skb_unmap(rocker, attrs);
rx_len = rocker_tlv_get_u16(attrs[ROCKER_TLV_RX_FRAG_LEN]);
skb_put(skb, rx_len);
skb->protocol = eth_type_trans(skb, rocker_port->dev);
if (rx_flags & ROCKER_RX_FLAGS_FWD_OFFLOAD)
skb->offload_fwd_mark = 1;
rocker_port->dev->stats.rx_packets++;
rocker_port->dev->stats.rx_bytes += skb->len;
netif_receive_skb(skb);
return rocker_dma_rx_ring_skb_alloc(rocker_port, desc_info);
}完成上述分析后,我们应该知道了cmd和event中断是接口配置命令的, tx和rx是处理芯片发送和接收报文的。
让我们揭开上面提到了问题,其实如果你用“rocker driver”在搜索引擎中找一下的话,会发现第一个结果就是介绍rocker的:Rocker: switchdev prototyping vehicle。这个文件里介绍了rocker设备的一些主要实现原理,简单来说Rocker就是QEMU模拟的一个交换芯片设备,通过cmd和event分别实现对设备的配置,以及设备事件的上报,通过tx和rx实现报文的收发功能,如果对Rocker设备有兴趣,可以去看看QEMU的源代码,看文档中的介绍,Rocker设备最终是通过tun机制模拟了交换芯片的端口功能。
其实,上面这么多内容都是介绍Rocker驱动的,我们的主角switchdev还没有出场呢,那么他在哪里呢?在rocker_probe中有如下代码:
/* Only FIBs pointing to our own netdevs are programmed into
* the device, so no need to pass a callback.
*/
rocker->fib_nb.notifier_call = rocker_router_fib_event;
err = register_fib_notifier(&init_net, &rocker->fib_nb, NULL, NULL);
if (err)
goto err_register_fib_notifier;
err = register_switchdev_notifier(&rocker_switchdev_notifier);
if (err) {
dev_err(&pdev->dev, "Failed to register switchdev notifier\n");
goto err_register_switchdev_notifier;
}
nb = &rocker_switchdev_blocking_notifier;
err = register_switchdev_blocking_notifier(nb);
if (err) {
dev_err(&pdev->dev, "Failed to register switchdev blocking notifier\n");
goto err_register_switchdev_blocking_notifier;
}其中rocker_switchdev_notifier和rocker_switchdev_blocking_notifier的实现如下:
static struct notifier_block rocker_switchdev_notifier = {
.notifier_call = rocker_switchdev_event,
};
static struct notifier_block rocker_switchdev_blocking_notifier = {
.notifier_call = rocker_switchdev_blocking_event,
};具体说就是rocker_router_fib_event处理fib变化的事件,包括如下事件:
enum fib_event_type {
FIB_EVENT_ENTRY_REPLACE,
FIB_EVENT_ENTRY_APPEND,
FIB_EVENT_ENTRY_ADD,
FIB_EVENT_ENTRY_DEL,
FIB_EVENT_RULE_ADD,
FIB_EVENT_RULE_DEL,
FIB_EVENT_NH_ADD,
FIB_EVENT_NH_DEL,
FIB_EVENT_VIF_ADD,
FIB_EVENT_VIF_DEL,
};rocker_switchdev_event处理switchdev通用事件,包括如下事件:
enum switchdev_notifier_type {
SWITCHDEV_FDB_ADD_TO_BRIDGE = 1,
SWITCHDEV_FDB_DEL_TO_BRIDGE,
SWITCHDEV_FDB_ADD_TO_DEVICE,
SWITCHDEV_FDB_DEL_TO_DEVICE,
SWITCHDEV_FDB_OFFLOADED,
SWITCHDEV_FDB_FLUSH_TO_BRIDGE,
SWITCHDEV_PORT_OBJ_ADD, /* Blocking. */
SWITCHDEV_PORT_OBJ_DEL, /* Blocking. */
SWITCHDEV_PORT_ATTR_SET, /* May be blocking . */
SWITCHDEV_VXLAN_FDB_ADD_TO_BRIDGE,
SWITCHDEV_VXLAN_FDB_DEL_TO_BRIDGE,
SWITCHDEV_VXLAN_FDB_ADD_TO_DEVICE,
SWITCHDEV_VXLAN_FDB_DEL_TO_DEVICE,
SWITCHDEV_VXLAN_FDB_OFFLOADED,
SWITCHDEV_BRPORT_OFFLOADED,
SWITCHDEV_BRPORT_UNOFFLOADED,
};rocker_switchdev_blocking_event处理port相关事件,包括如下事件:
enum switchdev_notifier_type {
SWITCHDEV_FDB_ADD_TO_BRIDGE = 1,
SWITCHDEV_FDB_DEL_TO_BRIDGE,
SWITCHDEV_FDB_ADD_TO_DEVICE,
SWITCHDEV_FDB_DEL_TO_DEVICE,
SWITCHDEV_FDB_OFFLOADED,
SWITCHDEV_FDB_FLUSH_TO_BRIDGE,
SWITCHDEV_PORT_OBJ_ADD, /* Blocking. */
SWITCHDEV_PORT_OBJ_DEL, /* Blocking. */
SWITCHDEV_PORT_ATTR_SET, /* May be blocking . */
SWITCHDEV_VXLAN_FDB_ADD_TO_BRIDGE,
SWITCHDEV_VXLAN_FDB_DEL_TO_BRIDGE,
SWITCHDEV_VXLAN_FDB_ADD_TO_DEVICE,
SWITCHDEV_VXLAN_FDB_DEL_TO_DEVICE,
SWITCHDEV_VXLAN_FDB_OFFLOADED,
SWITCHDEV_BRPORT_OFFLOADED,
SWITCHDEV_BRPORT_UNOFFLOADED,
};上面这三大类事件的通知,需要业务模块,比如brdige, fib等,分别调用call_fib_notifiers,call_switchdev_notifiers和call_switchdev_blocking_notifiers,其中call_fib_notifiers是fib自己实现的通知机制,后面两个都是switchdev实现的通知机制。调用这些接口不限于bridge和fib模块,一些网卡驱动也可能会触发,比如下面这些,数据来自这里:
drivers/net/ethernet/marvell/prestera/prestera_switchdev.c
line 1212
line 1803
line 1807
drivers/net/ethernet/mellanox/mlx5/core/esw/bridge.c, line 32
drivers/net/ethernet/mellanox/mlxsw/spectrum_router.c
line 10621
line 10669
drivers/net/ethernet/mellanox/mlxsw/spectrum_switchdev.c
line 3016
line 3042
line 3416
line 3429
line 3574
line 3595
drivers/net/ethernet/microchip/lan966x/lan966x_mac.c, line 270
drivers/net/ethernet/microchip/sparx5/sparx5_mactable.c, line 286
drivers/net/ethernet/rocker/rocker_main.c, line 2710
drivers/net/ethernet/rocker/rocker_ofdpa.c, line 1834
drivers/net/ethernet/ti/am65-cpsw-switchdev.c, line 362
drivers/net/ethernet/ti/cpsw_switchdev.c, line 372
drivers/net/vxlan/vxlan_core.c, line 318
drivers/s390/net/qeth_l2_main.c
line 292
line 652
line 658
net/bridge/br_switchdev.c
line 100
line 166
line 170
net/dsa/port.c, line 51
net/dsa/user.c, line 3553
net/switchdev/switchdev.c, line 517之所以会出现这种情况,是因为switchdev有很多通知类型,设备完成FDB表项卸载后,可以发送SWITCHDEV_FDB_OFFLOADED通知其他模块,其他模块关心这个事件可以自己处理,不关心不处理即可,比如bridge模块的br_switchdev_event就处理了SWITCHDEV_FDB_OFFLOADED事件,因为只有这样bridge才知道该FDB表项被真的offload了。除此之外,当设备上学习了动态MAC地址,也会通过SWITCHDEV_FDB_ADD_TO_BRIDGE事件再通知bridge模块,bridge标记为硬件学习,后续的老化也是需要硬件更新。
switchdev还为厂商实现自己的驱动提供了一些通用接口,比如switchdev_handle_fdb_event_to_device,switchdev_handle_port_obj_add,switchdev_handle_port_attr_set,switchdev_bridge_port_offload等,这些接口内部通过递归调用的方式支持bridge和LAG设备,并调用驱动注册的具体接口实现,或者实现offload完成通知消息的发送功能。
至此我们完成了switchdev驱动框架的主要代码分析工作,其实rocker驱动将表项卸载到了哪里,我们这里都没有提及,如果有兴趣可以看看rocker_ofdpa.c这个文件,看看rocker内部是通过什么实现的。因为和switchdev关系不大,我们这里就不详细介绍了。
本文代码主要交互流程:
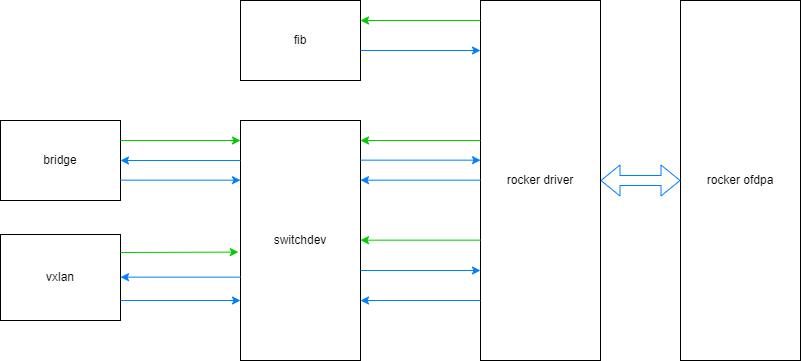
绿色箭头是注册流程,蓝色箭头是通知流程,注意蓝色箭头两个方向都支持。
参考文档
- Linux Switchdev the Mellanox way 一个使用Mellanox芯片基于switchdev模型的交换机示例
- Switchdev:释放开源Linux的网络力量 switchdev框架介绍,DENT操作系统,以及一个应用案例
- Linux 4.0的switchdev 绘制了Linux switch软硬件框架流程图,并展示了硬件卸载实现的Linux Box案例